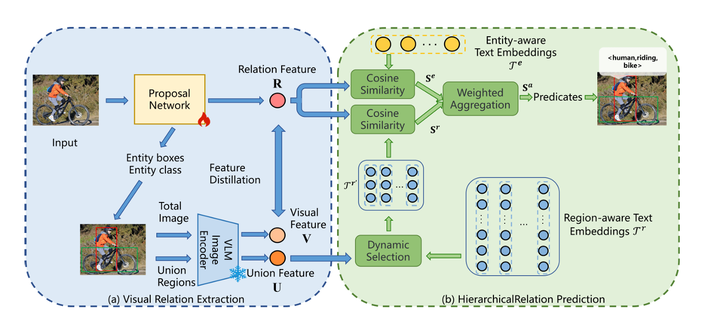
 An overview of RAHP. (a) Visual Relation Extraction Module: The process begins with extracting relation proposals and their features from the image, which are then encoded into visual features using a VLM. (b) Hierarchical Relation Prediction Module: The visual features undergo a guided selection process, where the selected embeddings are combined with entity-aware embeddings to predict predicates.
An overview of RAHP. (a) Visual Relation Extraction Module: The process begins with extracting relation proposals and their features from the image, which are then encoded into visual features using a VLM. (b) Hierarchical Relation Prediction Module: The visual features undergo a guided selection process, where the selected embeddings are combined with entity-aware embeddings to predict predicates.
Abstract
Open-vocabulary Scene Graph Generation (OV-SGG) addresses closed-set limitations by aligning visual and textual representations, but existing methods suffer from fixed text representations that hinder alignment accuracy and diversity. We propose RAHP (Relation-Aware Hierarchical Prompting), a framework enhancing text representations via entity-aware and region-aware hierarchical prompts. RAHP uses entity clustering to reduce triplet complexity, leverages LLMs to generate fine-grained region prompts, and adopts a VLM-guided dynamic selection mechanism to filter irrelevant prompts. Trained with multi-task loss (bounding box regression, entity/predicate classification, distillation), RAHP achieves state-of-the-art performance on Visual Genome and Open Images v6 datasets, validating its effectiveness in OV-SGG tasks.